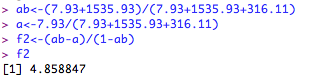
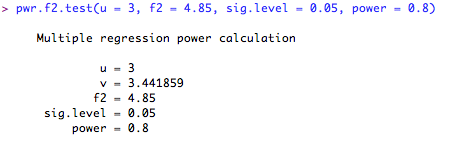
Calculate effect size:
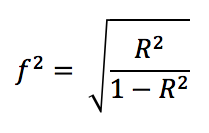
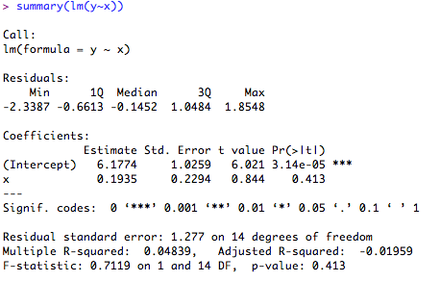
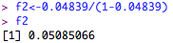
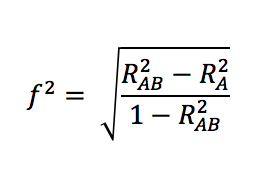
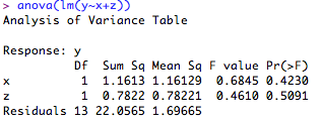
Consider the regression we carried out previously (y ~ x). Now, we add a second continuous variable (z) to the regression to make y ~ x + z. What we want to know is the unique amount of variance accounted for by variable 'x'. If we ask R for the summary of the lm model, this will give us the overall R2, but as we need individual values, we need to ask R to give us a little more information. We can do this by asking for the ANOVA table of the regression:
Calculate sample size:

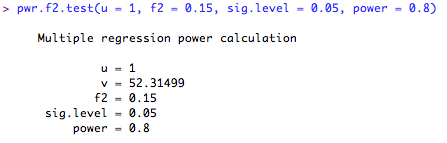
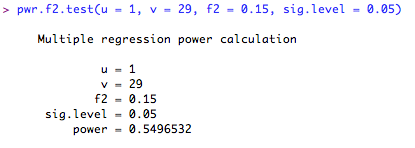
This is a little complicated, so let's try an example in R. First, we type our model into R, and ask for the ANOVA table so we can see the sums of squares estimates.
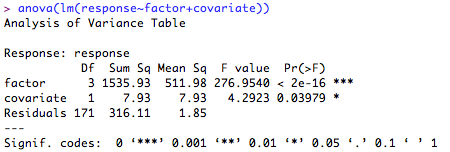
Imagine, for example, our factor is 'region where the subject lives' (i.e., North, South, East, West), our covariate is 'Body Mass Index', and our response is 'Units of Alcohol consumed in a week'. So we want to know how many units are consumed as a function of location, but we want to control for the effects of BMI. As you can probably see, we can select on the basis of where someone lives to repeat this, but we are unlikely to get the same BMIs corresponding to the same unites of alcohol again, so we need to partition this out of the effect size calculation.
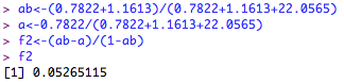
Using the nomenclature above, let's call the variance of our categorical factor 'B' and the total variance of our factor and covariate 'AB'. Let's type this into R: